|
|
2022 Linux 内核十大技术革新功能 | 年终盘点 (qq.com)
本文来自 CSDN 重磅策划的《2022 年技术年度盘点》栏目。2022 年,智能技术变革留下了深刻的脚印,各行各业数字化升级催生了更多新需求。过去一年,亦是机遇与挑战并存的一年。
在本篇文章中,长期奋斗在一线的 Linux 内核开发者宋宝华老师为大家解剖 2022 年 Linux 内核开发的十大革新技术功能,纪念这平凡而又不凡的 Linux 内核之旅。
作者 | 宋宝华 责编 | 梦依丹
出品 | CSDN(ID:CSDNnews)
滚滚长江东逝水,浪花淘尽英雄。在浩瀚的宇宙星河中,波卷云诡的 2022 年,纵使无数渺小如尘埃般人类个体的命运伴随着群体宏大叙事的转折变迁而风雨飘摇,也只是再平淡不过的一年。很多年以后,人们会忘却了 2022 年的人和事。然而,Linux 内核在 2022 年发生的重大事件,仍然在若干年后会潜移默化地影响着无数人,时间会消磨一切,唯有文字和代码可以永恒。
2023 年的农历新春即将到来,注定将是一个几家焰火几家忧伤的春节,人类的悲欢总是不尽相同。而卑微如笔者,也唯有在一个遥远的地球角落,写一些文字来纪念这一年平凡而不凡的 Linux 内核。
这一年,Linus Torvalds 迎来了他生命的第 54 年,好友 dog250 前些天发朋友圈说,Linus 可能最多还能管 Linux 内核 36 年,一些公司甚至以在内核社区提交补丁作为 KPI,所以内核可能会越来越臃肿,36 年后的 Linux,必将成为一坨屎。我劝他说,我们也不一定能再活 36 年,超那份心干啥呢?
窃以为,Linux 内核,将以顽强的生命力,活过使用 Linux 的很多码农,直到下一个革命性操作系统的出现。前提是,Linux 内核仍然总体是技术和社区驱动的,不会成为某一特定商业公司挟天子以令诸侯的筹码,更不能成为无数人追名逐利的名利场。
2022 年,Linux 内核共发布了 5.16、5.17、5.18、5.19 和 6.1 五个版本。社区以顽强的驱动力激发内核的活力,海外友商,以及我国华为、阿里、腾讯、字节等头部企业的联合努力,一众新 feature 加入内核,本文一一盘点 Linux 内核 2022 年十大技术革新。这个榜单,为笔者个人之理解,如有意见雷同,纯属巧合;如有不同意见,则纯属意外。
首先列一下提纲形成一个总体的认识:
- Multi-generational LRU
- 内核调度器 cluster 调度支持及 AMD ZEN 的 LLC imbalance
- 基于 DAMON 的 LRU-lists Sorting
- 基于 DAMON 以及 per-memcg 的 proactive reclaim
- maple tree
- MADV_COLLAPSE、futex_waitv 等 API
- Memory tiering 的 demotion/promotion 一系列优化
- Rust 和 C11
- 热闹非凡的 BPF
- 龙芯新架构 LoongArch 引入 5.19 内核主线
故事的大幕正式拉开......
  编辑 编辑
Multi-generational LRU
Least Recently Used (LRU)是计算机体系架构的一个永恒经典话题,只要cache 比 memory 贵和快,memory 比 disk 贵和快,人们都需要在房价和房子大之间找到一个平衡。Linux 内核,以 LRU 算法管理内存和磁盘 I/O 之间的替换。它把 LRU 分为 File 和 anon 页,尔后 File 和 anon 页各自有自己的 active 和 inactive list,活跃的页面从 inactive 升级到 active list,冷却的页面从 active 页面降级到 inactive list,直至足够冷却,排在了 list 的尾部,被内核回收。
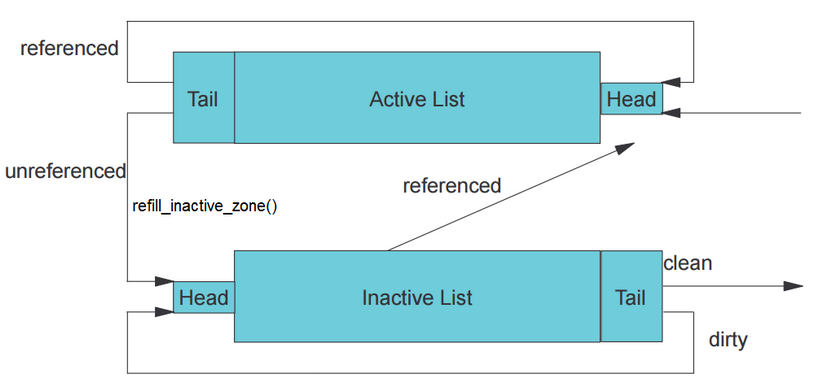
这个算法的主体逻辑维持了多年,虽性能欠佳却异常坚强。Google 的 Zhao Yu 童鞋,打破固有局势,向 Linux 内核社区贡献了 Multi-generational LRU(MGLRU)。
我们来看看 MGLRU 的底层逻辑是什么。作为一个 LRU 算法,我们任何时候其实有 2 个方面的诉求:一是选择出被回收页面的精准度,被回收的页面最好是未来较长时间不使用的页面;二是算法成本,如果算法的成本特别高,哪怕回收地特别精准,实际效果也会非常差,不如来个不那么精准的。
实际上,Linux 内核的 LRU 在算法成本上可能极高,一个简单的事实是,现代 CPU 通常会在页表 Page Table Entry(PTE)中含有一个 reference bit,如果硬件访问过这一页,这个 bit 会被硬件自动设置,这个 PTE 对应的 page 会被内核识别为 young(青春年少)。在 LRU 算法的 active、inactive 变迁,以及页面回收时,我们是通过扫描 PTE 的 reference bit 来决定页面是否 young 的。但是,当一个页面被许多进程共享的时候,比如 100 个进程,我们则需要通过所谓的反向映射技术,找到这 100 个进程的 100 张页表,来一一读取 PTE 的 reference bit:
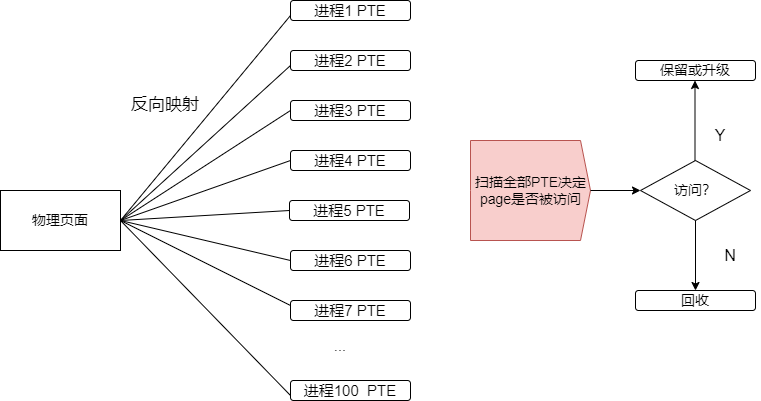
在我们进入内存回收路径时,通常系统的空闲内存已经很少。而我们为了进行回收,还需要以上漫长复杂的过程,这个时候我们往往会感受到系统的卡顿。如果我们能够根据页面回收时候的成本,进行有针对性的回收决策,则可能进一步优化 LRU。比如,典型的,透过 syscall 访问的文件 pagecache,可能没有被任何进程 map,扫描的时候可能就不需要上述的反向映射过程,成本就可能比文件中被广泛映射的代码段之类低很多。
再者,内核 LRU 算法,在精度上可能也有问题,比如,file 和 anon 是两个单独的 list,我们可以在 file 和 anon 内部进行 page 热度的排序,但是很难对比和评估 file 与 anon 页面之间的热度。
MGLRU 抛弃了 active、inactive 两种不同类型 list 的概念,取而代之的是 2 个新概念:Generation 和 Tier。
MGLRU 最年轻的一代是 max_seq,其对于 anon 和 file 来说,总是相等的;最老的一代,则区分为:min_seq[anon] 和 min_seq[file]。因为内存回收的时候,允许 file 比 anon 更激进地多回收一代,所以 anon 和 file 的 min_seq 不一定完全相等。
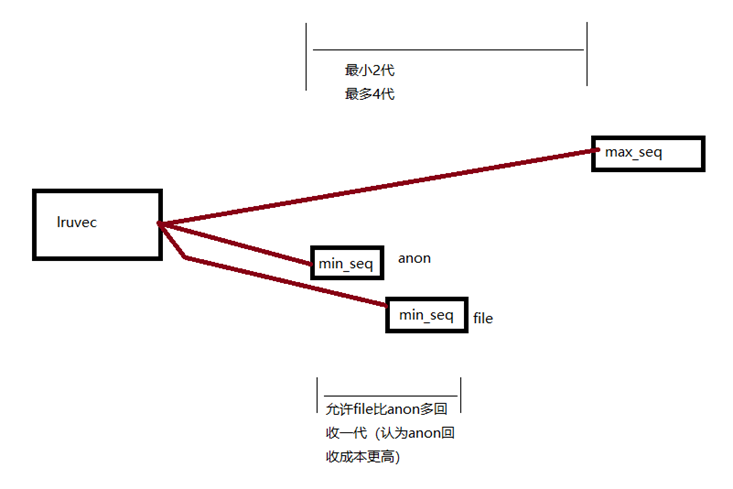
MGLRU 为 file 和 anon 页面维护了 4 代 LRU list,不再有 active 和 inactive 的“类 2 代”概念。通过 min_seq 和 max_seq 的增加来更新代。相关的细节比较复杂,我们用最简单的图示来推演下 MGLRU 的工作。
假设我们观察的起点,min_seq=100,max_seq=103,分别装有a,b,c,d,e,f,h,i 这 8 个 page:

现在我们把 b 访问一下,那么 b 可以被 promote 到 max_seq=103 的一代:

这个时候,我们进行内存回收,min_seq=100 的 page a 可能就被回收了,当然,min_seq 就变成了 101。

这个过程一直是动态的,随着不断有新的 page 进入,随着内核内存的不断回收,过了一会,它可能就变成这样了:

b 和 i 目前还在 max_seq 最新代 108,证明过去有段时间里面它们被访问地比较频繁啊!
MGLRU 可以限制 anon 和 file 的 min_seq 的代差,实际很好地平衡了 anon 和 file 的回收。
前面我们提到,mapped 的 page 的回收成本远大于仅仅通过 syscall 进入 page cache 的 page。而且通常应用程序对 syscall 的 I/O 可能会精心设计,哪怕 page cache 扔掉再次 load 回来可能也不会太慢。比如让 syscall I/O 与其他过程异步并行;但是,对于运行过程中,突然 page fault 发生的 map 页面的同步读入,application 通常没有那么精心的准备。MGLRU 的另外一个概念 tier,实际是为了虐待 syscall 引入的 page 而善待被映射的 page。Tier 是 generation 内部的概念。代表文件 I/O 页的访问频度,如果文件页被访问 n 次,则其 tier 为 log2(n)。注意这个次数只在 sys_read、sys_write 的时候统计,故通过 system call 只被 read() 了一次的 page、只 map 访问的 page,tier 都是 0;通过 syscall 读写 2 次的 page,tier 是1。file page 首次通过 syscall read 进入的话,会进入 min_seq。而任何时候,基于 page fault 进入的 file 页(也就是被 map 到 PTE),都会直接进入 max_seq。
Tier 会基于一个 PID(Proportional–Integral–Derivative Control)反馈系统,根据 workingset 的 refault 情况,将 Tier(n) 的 refault 情况与 Tier(0-1) 的进行比对,计算出一个 tier index 作为参考,当 page 的访问次数的对数(log)超过这个 tier index,则可被升级到下一代 min_seq + 1(还是不升级到 max_seq 有木有)。MGLRU 之前的内核 LRU,会在页面第 2 次被 syscall 访问的时候,activate 一个 page 进入 active,而 Tier 在此 access 路径上不做这样的事情,syscall 的 page 仅仅可能在访问次数频繁的情况下,升一代而已。
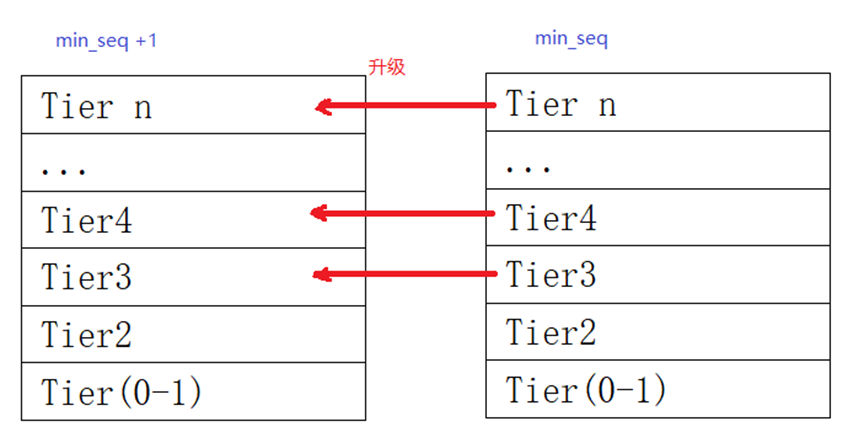
另外,原先内核 LRU 的设计,通常会通过二次尝试法, mapped 的 page 也是一次访问进入 inactive,二次访问再进入 active(除非是代码段、或被多个进程同时访问到了、或之前回收的页面再进来因 workingset 保护以避免 thrashing,可以一次性升级);这避免了把只访问一次的 page 提升到 active 难以回收的状态,可能有些 workload 可能就是把某些内存只访问一次呢?
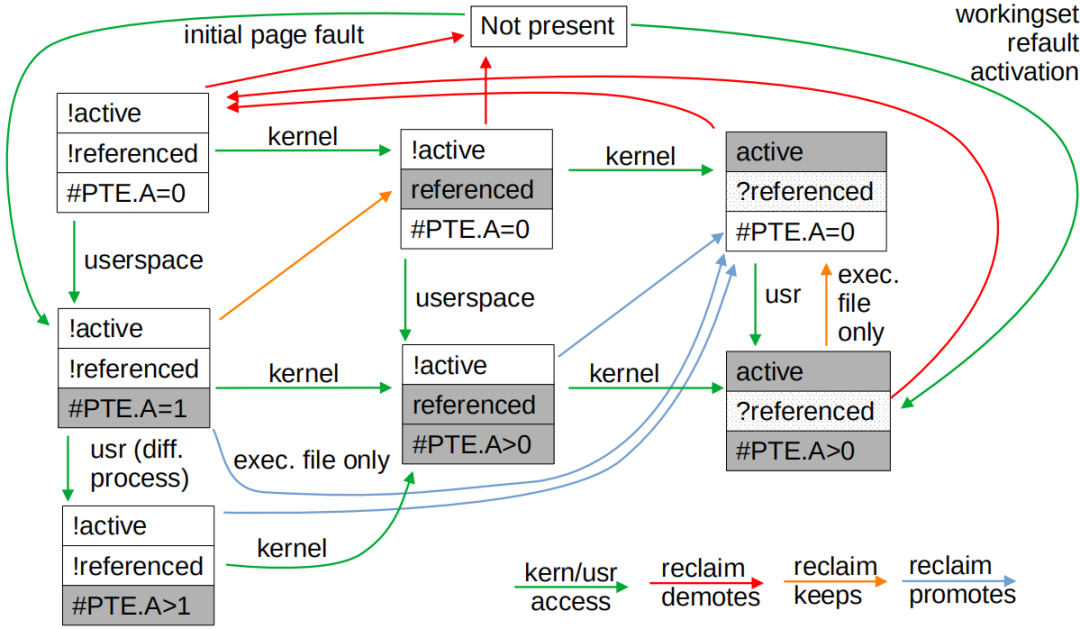
但是,MGLRU 对于 mapped 的 page 升级,都是一次性升级到 max_seq 最新代。对此,Zhao Yu 同学的解释是,Google 大量的数据采集显示,刚访问的内存对于用户体验来说是最重要的,这也不无道理。比如你在系统上打开个微信,微信访问了 mapped 的一些内存,这个时候微信是最重要的,直接给他顶到最高代而不是类似原 LRU 先放 inactive(这样它有更多可能性被替换),可以避免其他后台的任务需要内存的时候,碰巧把微信的 page 替换出去。当然,MGLRU 这样的“活在当下”的做法,对于特定的 workload 可能确实是有不良的副作用的。
MGLRU 有一个非常有特色的地方,它在通过反向映射查看 PTE 的 reference bit 时,会利用空间局部性原理,look-around 特定 PTE 周围的几十个 PTE,比如下图目标黑色 PTE 周围的红色 PTE:
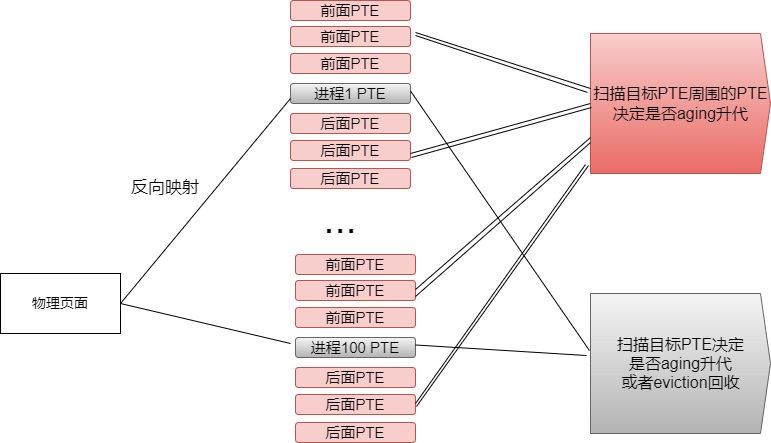
简单来说,我们既然通过反向映射好不容易找到了那个进程的 PTE,那么访问这个 PTE 周围的 PTE 是比较快的,我们就一起看,看完发现这个周围的 PTE 是 young 的,则升级它们到 max_seq。简单来说,你在武汉,你大伯父在上海,你坐高铁去上海看你大伯父。但是你二伯父正好也是在上海,你肯定把你二伯父也一起看一看。何必不看呢?人已经到上海了,下次再看二伯父,不是还是要通过反向映射,坐高铁从武汉到上海?这一 look-around 的创意,显然极大降低了我们前面提到了回收时 rmap 查询 page young 的开销。
MGLRU 还有一些有意思的优化,比如正向扫描进程页表进一步利用空间局部性减小 rmap 的开销;基于时间的 thrashing 阻止(防止 page 反复回收和因为重新 access 进入 LRU)等。
内核调度器 Cluster 调度支持及 AMD ZEN 的 LLC imbalance
Cluster 调度器,这一由笔者提出和主要参与,海思 Jonathan Cameron,Yicong Yang 和 Intel Tim Chen 等童鞋联合开发的调度器 feature 合入 2022 年一月发布的 5.16 内核,被列入为 5.16 “prominent features”之一。
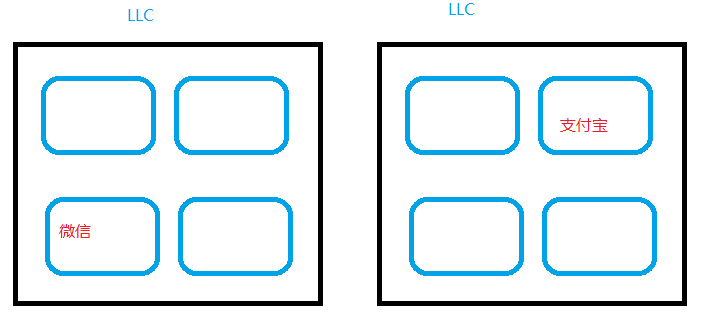
我们简单地介绍一下这个工作的背景。Linux 内核有较好的 last level cache(通常是 L3 cache)意识,在调度器的负载均衡场景,它可以把任务铺开到不同的 LLC domain,从而让任务享有更多的 cache 资源,并减小 cache 之间的 contention。比如系统有 8 个 CPU,每 4 个共享一个 LLC,运行微信和支付宝两个任务,下面的运行方式可能较为理想,微信和支付宝在 2 个分开的 domain 里面运行,有利于最大化它们各自能拿到的系统资源。
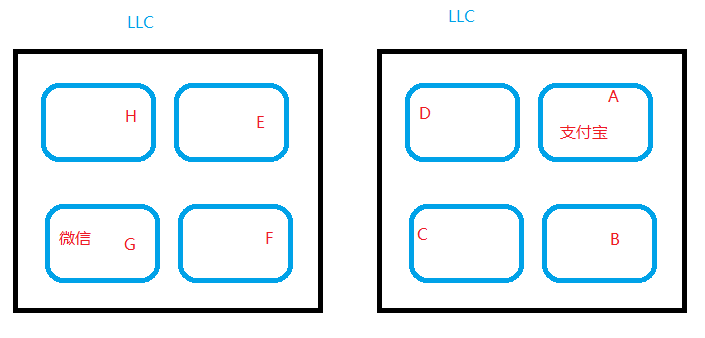
但是在任务唤醒的场景,则通常希望借助同 LLC domain 内 cache 的临近优势,让任务唤醒后更平滑获得 cache 迁移。比如 CPU A 上面的支付宝睡眠了,我们从 CPU B 上某任务唤醒它:
理论上,支付宝继续在 A 上面跑会比较好,因为睡眠之前的 cache 之类可能还在。但是 A CPU 可能很忙,支付宝在 A 上面跑,可能要等很久,这个时候我们可以优先考虑 B,C,D,它们与 A 邻近,相对而言的 cache 迁移成本低,而不是考虑把被唤醒的支付宝放置于遥远的 E,F,G,H。注意,实际的 wake_affine() 处理比这个复杂地多,这只是一个简化模型。
但是,Linux 的调度器,并不考虑 LLC 之前的可能的 L2 或者中间阶段 cache。假设一个系统有 4 个 CPU,全部共享一个 LLC,但是每 2 个共享一个 L2 cache。由于调度器没有 LLC 以外的 cache 概念,内核会认为 4 个 CPU 对等,则负载均衡的结果完全可能是:
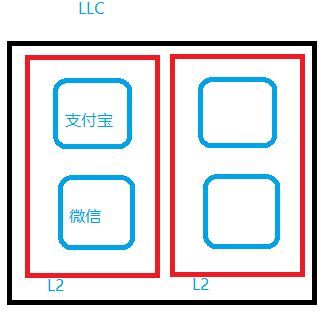
这样没有关联的支付宝和微信运行在同样一个 L2 上面的 cache contention 较大。Cluster scheduler,旨在让调度器意识到 LLC 之前的 cache 级别或其他拓扑级别,从而有针对性地进行负载均衡和 wake_affine 处理。
上面同样的 4 个 CPU,增加 cluster scheduler 后,负载均衡的结果会是:
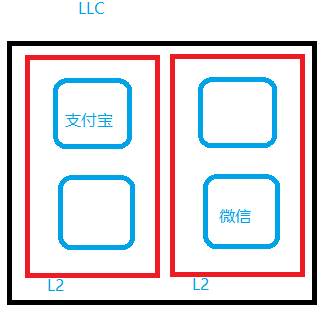
Cluster 调度器,会对带有中间阶段 cache/拓扑级别的处理器调度带来性能提升,典型应用于 ARM Kunpeng920、X86 Jacobsville 等处理器平台。
同样基于 cache 拓扑,对调度进行优化的,还有合入 5.18 内核的“Better process scheduling performance on AMD Zen”,这一贡献来自于大名鼎鼎的 Mel Gorman,他调整了同一个 NUMA 节点内,多个 LLC domain 的调度不平衡。如下图,来自 Intel X86 的处理器通常是一个 NUMA 节点共享一个 LLC 的。
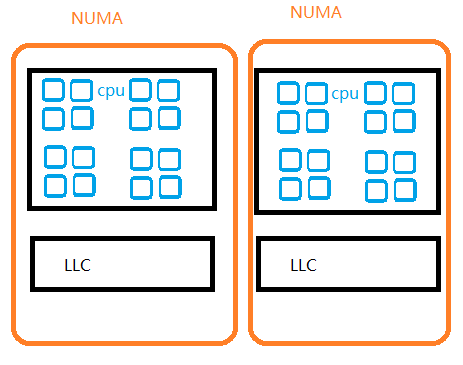
调度器在进行调度的是,任务会在两个不同的 NUMA 节点间进行负载均衡。从而导致 task 在 NUMA 间迁移。但是,允许两个 NUMA 间少量的不平衡,则可以避免这种迁移过于频繁,尤其在负载比较轻的情况下。这类似一个人月薪一万,另外一个人月薪九千五,给这两个人搞平均,意义不大,最后两个人都不开心。月薪一万和月薪一千的人,搞一搞还是可以的。
AMD ZEN 的体系架构与 Intel 的处理器有点不一样,它在同一个 NUMA 内部,也是 LLC 有多个的:
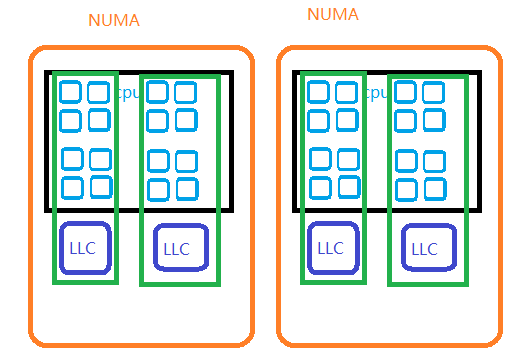
比如每 8 个 CPU 一个 LLC(以上拓扑仅为示意图,与真实 CPU 数量等不一定一致)。这样 LLC 成为一个比 NUMA 更小的需要考虑不平衡的 domain,因为任务在 LLC 之间迁移的开销应该也是比较大的。Mel 的提交“sched/fair: Adjust the allowed NUMA imbalance when SD_NUMA spans multiple LLCs”,允许了这种 NUMA 内部,LLC 之间的少量不均衡,从而减小不必要的任务迁移,通过调度优化提升了 AMD ZEN 上 workload 的运行性能。
基于 DAMON 的 LRU-lists Sorting
DAMON 是来自 amazon SeongJae Park 童鞋的心血之作,是 Linux 内核的一个 data access monitoring 框架。LRU-lists Sorting 是 DAMON 框架下的一项工作。
Linux 内核的 LRU 算法,相对来说是缺乏进取心的,是在内存相对紧张的时候才开始运行的。前面说的 active、inactive list,基本在内存相对宽裕的情况下,没有人去造访。我们都清楚,Linux 的内存回收是水位驱动的:
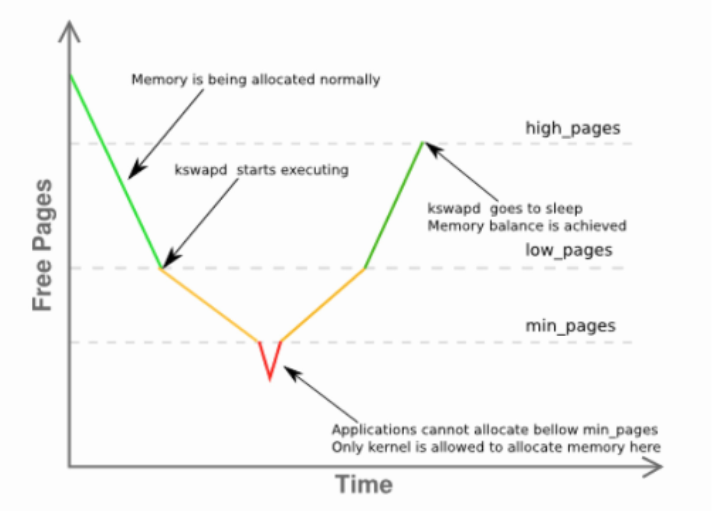
达到 low 水位的时候,kswapd 开始异步回收内存;达到 min 水位的时候,进程被堵住进行 direct reclamation 同步回收内存。
在回收的时候,我们扫描 inactive list 尾部的一个个 page,但是仍然需要通过反向映射读这些 page 的 PTE 的 reference bit,如果这些 page 曾经被访问,我们还是不能回收它(它们可能回到 inactive 或者 active 的头部);只有红色的那些老 page,正好由于扫描前没有被访问,才被回收。所以,回收成本高,回收效率低。
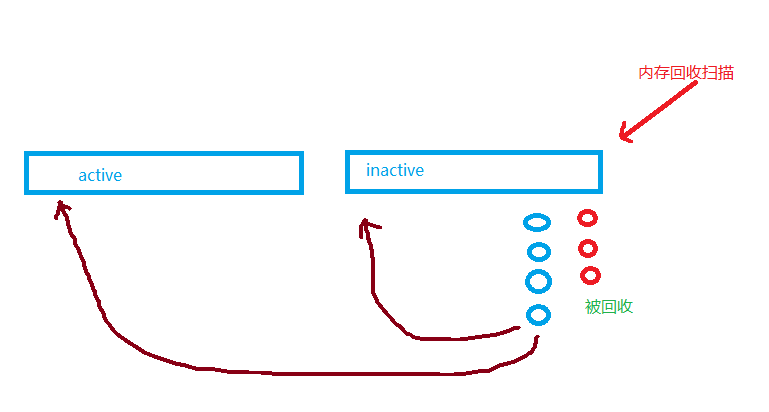
这是极有可能发生的,考虑到内存压力到来前,LRU 算法在 Linux 内核基本是一个躺平的状态。累积到 inactive 尾部的 page 的 PTE,可能由于长期没有被扫描到,其状态并不能反映页面实时的情况。上图中,扫描了 7 页,仅回收了 3 页,这个效率是很低的。
基于 DAMON 的 LRU-lists Sorting 这个项目的 idea,其实是在内存压力到来前,进行进取型地 LRU 排序,先把热页找出来,往 LRU 的头部提升,这样 LRU 的尾部相对容易是冷页,从而提升回收效率,比如下图中,我们得到 5 个被回收的红球。
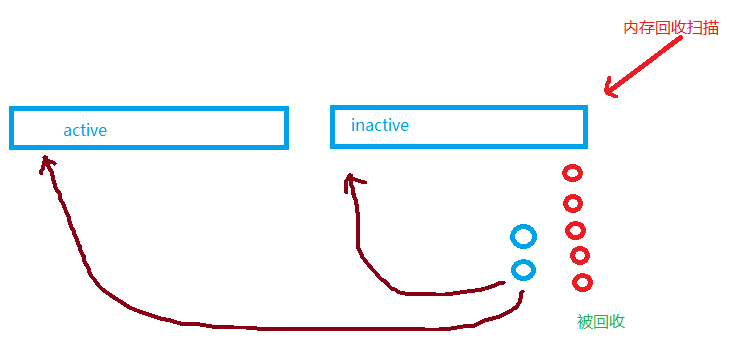
DAMON 的 LRU-lists Sorting 毫无疑问提供了一个极好的 idea,但是笔者对它的实际效果是持怀疑态度的。这主要源于,DAMON 采用的是类似大海里找飞机残骸的方式来寻找热页的。这个方式并不靠谱。
DAMON 把一片庞大的物理内存区域进行分割,然后在每一片分割的内存区域随机找一个地址去访问,如果它在这个地址上发现这个页面的 PTE 是有 reference bit 的,则进一步把这个 PTE 所在的区域进行继续分割缩小,盯着这个位置看。
简单来说,有一架飞机在茫茫的太平洋上空炸了,残骸可能分布在太平洋某处方圆数十公里的范围。于是你派出 100 个搜寻队,然后把太平洋分成 100 块。每个搜救队,随机在自己分得的区域找个点去搜索,如果它找到了一个小残骸,它可以进一步围绕这个残骸的周围密集搜索。这样把搜索范围逐步缩小,找到这架飞机全部的残骸甚至黑匣子。
这个方式用在内核里面并不靠谱,原因有二:
- 内核的物理地址空间太大了,茫茫太平洋随机打点,可能要打很多次才能找到一点残骸;
- 由于 Linux 内核普遍采用虚拟地址到物理地址的转换,内核的物理地址空间不太具备空间局部性。
问题 1 比较好理解,问题 2 理解 MMU 工作原理的童鞋应该很容易想明白。在进程的虚拟地址空间可能存在较好的空间局部性,但是连续的虚拟地址在物理地址上的映射往往是不连续的。所以不能简单假定你在物理地址 100MB 这个位置找到了一点残骸,就可以在 100MB 周围找到其他的残骸。
有鉴于此,在下基本认为这个工作本身应该是没有效果,但是它本身给出的想法,却具有极强的指引意义,指引我们不断努力求索更好的实现方式。

基于 DAMON 以及 per-memcg 的 proactive reclaim
基于 DAMON 的 proactive reclaim 也是 DAMON 框架下的一项工作,它仍然采用类似前文的大海里找飞机残骸的原理,进取型地在内存压力到来前回收一部分冷页,从而减缓内存压力的到来。
类似的工作,还有来自于 Google Shakeel Butt 和 Yosry Ahmed 童鞋的 per-memcg proactive reclaim。这项工作为内核增加一个新的用户态接口,比如你在特定的 memcg 里面“echo 10M > memory.reclaim”就可以触发这个 memcg 里面的内存回收工作。当把灵活性交给用户态的时候,用户态可以借用 refault 和 PSI 的反馈机制,灵活地进行回收控制,也可更早地对 LRU 进行排序。
运行 echo "1G" > memory.reclaim 的话,意味着我们期许回收 1G 的内存。
这项工作简单快捷,它的实现也是异常简单,简单地调用 try_to_free_mem_cgroup_pages() 去进行 memcg 的 LRU list 扫描和回收:

在下非常认同它的这个简单快捷,内核只提供机制,把策略交给用户态。
maple tree
下面闪亮登场的是来自 Oracle 大神 Matthew Wilcox 和 Liam Howlett 童鞋的火红枫叶树!现实生活中的枫叶树美地让人沉醉,内核里的枫叶树,代码读地你欲哭无泪,整个 patchset 有 70 个 patch。
 正在上传…重新上传取消 正在上传…重新上传取消
内核的进程 VMA 原本保存于一个被修改过的红黑树,受到位于 mm_struct 内的 mmap_sem(5.8 后更名为 mmap_lock)保护。mmap_sem 是 Linux 内核臭名昭著的大坑,这个锁的竞争也成为内核最重要的性能瓶颈之一。历史上,人们付出了无数的努力来降低这个锁的竞争,这里面最著名的莫过于在 page fault 的处理中,采用 SPF(Speculative page faults),尽可能避免去拿 mmap_sem 这个锁。简单来说,SPF 采用马伊琍童鞋“且行且珍惜”的方式,边走边看,先不拿 mmap_sem,但是每走一个关键步骤,就查询是否其他地方有并存的 VMA 以及 PTE 页表修改,如果有这种并发的过程,再考虑让 page fault 重新 retry,获取 mmap_sem。比如充满了这种“是否苍天变了心”的判断:
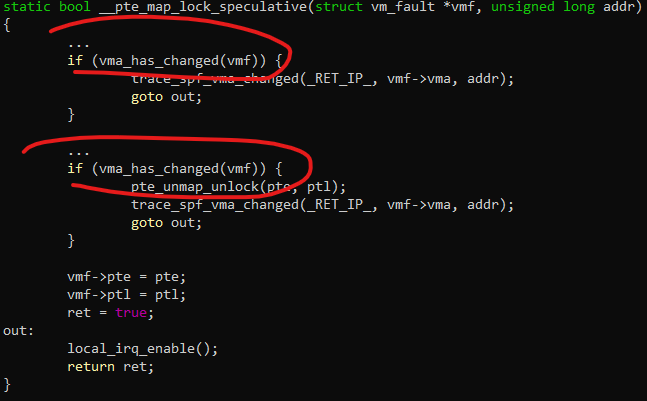
Maple tree 的理念不太一样,它从维护 VMA 的数据结构层面,进行根本性的革命。Maple tree 是一种 B-tree,支持 lockless 和 RCU 设计,针对 non-overlapping 的 range-based 的业务场景,目前已经替换维护内核 VMA 的 rbtree,因为一个进程的地址空间 mm_struct 显然包含多个 VMA,而且这些 VMA 是不会 overlapping。
遗憾地是,6.1 采用 maple tree 后的性能提升仅限于 cache miss 的减少。由于 maple tree 的叶子和非叶子节点上,都可以承载较多的分支因子(branch factor),故 maple tree 要比 rbtree 简短很多,所以更加 cache 友好:
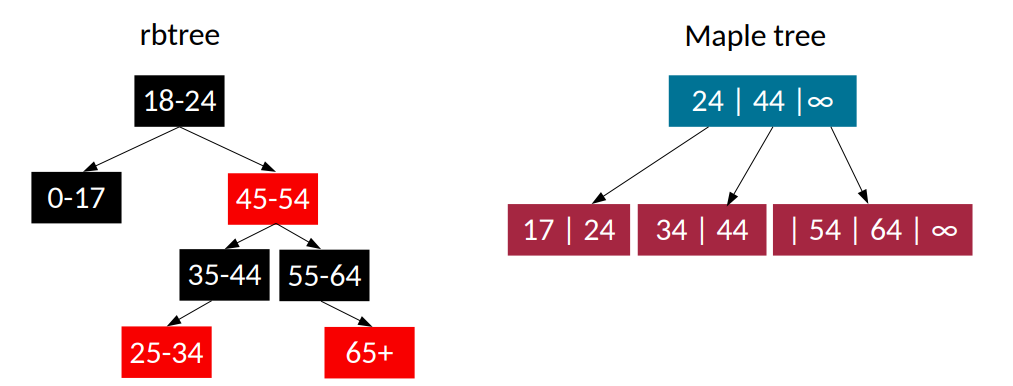
进一步地删除 mmap_lock、RCU 无锁化设计,仍然在计划中,开发目标是:采用 RCU 模式访问 maple tree,读者不会堵住写者,同一时刻只能有一个单一的写者,读者在碰到 stale data 的情况下,re-walk 获取 VMA,我们期待那一天的早日到来。

MADV_COLLAPSE、futex_waitv 等 API
透明大页(THP)的性能一直因为透明大页本身生命周期的不确定性而变幻莫测。首先,Linux 内核往往要经过一个 collapse 过程,把小页塌缩(collapse)为大页:
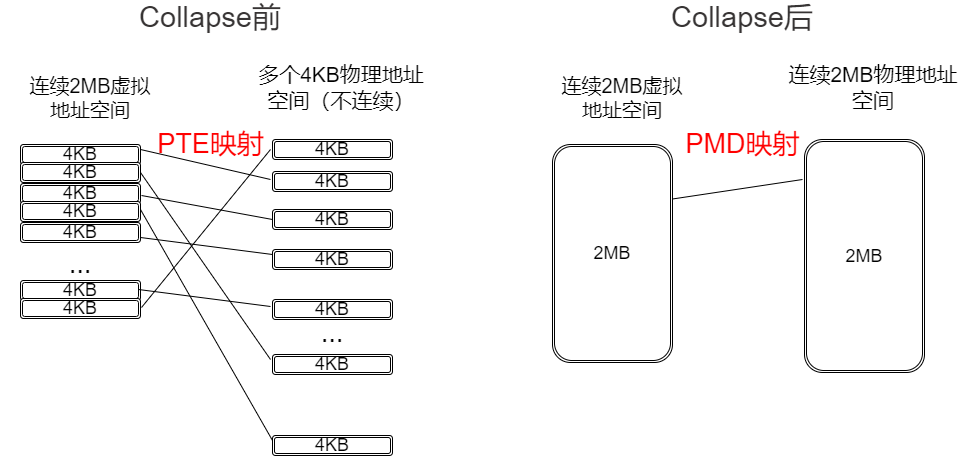
这个 collapse 过程是由内核后台线程 khugepaged 来异步完成的,但是这个过程非常不靠谱:
- 何时会 collapse 不知道;
- 是否值得 collapse 不太明确,比如你费了吃奶的力气给我塌缩成了大页,但是我进程又自己 free 了这个 2MB 内存或者 unmap,一切功夫都白费了。
我们能不能把这个事情变地靠谱和具有确定性呢?如果我的用户进程明确地知道我需要大页来降低 TLB miss,而且我这个大页会长期存在,我告诉你现在就给我 collapse 不香吗?来自 Google 的 Zach OKeefe 童鞋向内核贡献了 madvise 的 MADV_COLLAPSE API。
MADV_COLLAPSE 的语义比较直接,当我对你这 2MB 进行了 madvise 的暗示后,哪怕这个区域还有页面没有驻留,我会给你强制 fault in 或者 swap in(这有点 mlock 和 gup 的味道了);如果你有部分区域还没有映射,我给你把这部分初始化为 0,整个过程是同步完成的。
这里,我们回过头来看前文提到的 memory.reclaim 这个 feature,与 MADV_COLLAPSE 这个 feature 有些惊人的相似,就是内核经常不是万能的,把灵活性有时候要交给用户态,作为一个“架构师”,咱架构到了吗?
来自 collabora 的 André Almeida 童鞋,向内核社区贡献了一个新的系统调用:futex_waitv(),它实际被号称为 futex2 工作的一部分。
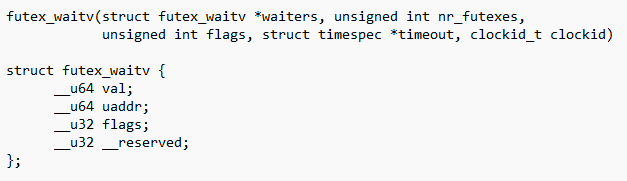
这个系统调用,允许用户态一次性等待多个 futex(fast user-space locking )锁,如果任何一个 futex 锁 ready 了,阻塞就返回,有那么一点 select 和 epoll 的味道。这为用户态的底层锁的库实现提供了支撑,模拟了 Windows 的 WaitForMultipleObjects() 行为,它可较好地替代 scalability 不太好的eventfd,从而提升游戏的帧率。

Memory tiering 的
demotion/promotion一系列优化
Memory tiering 是内核开发的热门领域之一,服务器为了追求性能、容量、成本之间的平衡(房子要大,房价要便宜),可能会配置分级的内存系统:
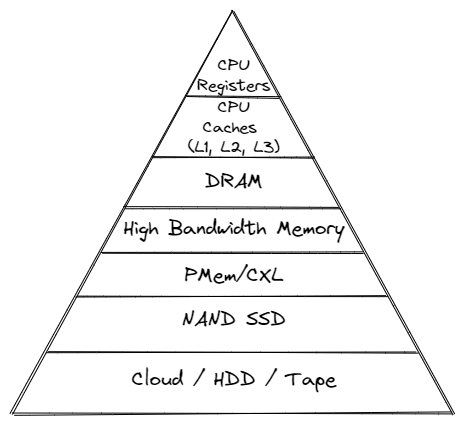
而那些单独的 DRAM 以外的 memory,比如 PMEM,可以成为单独的 cpu-less 的 NUMA 节点。比如如下硬件拓扑下 NUMA2-NUMA3,是两片单独的 PMEM。
经过 Alibaba 的 Yang shi、Intel 的 Ying Huang 和 Dave Hansen 等大神童鞋的共同努力,已经可以使得主存中的内存在进行回收的时候,也即 shrink_page_list() 的时候被迁移到速度更慢的 PMEM,而不是被回收进行 I/O,这个过程叫做 demotion。简单地说,目标是热内存在快区(higher tier),冷内存在慢区(lower tier)。
Intel 大神 Ying Huang 的另外一个 patchset,合入 5.18 内核的“NUMA balancing: optimize page placement for memory tiering system”,则进一步借助内核本身 NUMA balancing 时候内存在 NUMA Node 迁移的特性,把 PMEM 中的热页,迁移到 DRAM。
在原先的 Linux 内核中,左边 NUMA 节点的 CPU 疯狂访问右边 NUMA 节点的 DRAM 的时候,NUMA Balancing 是可以将右边 NUMA 节点的内存迁移到左边的:
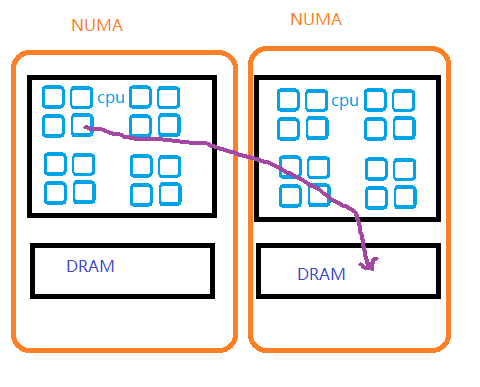
但是这一 NUMA Balancing 按照不同 NUMA 的内存是相同类型而设计,对于如下拓扑工作地并不好:
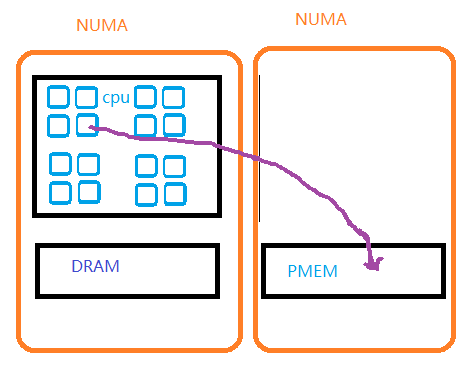
原先内核的 NUMA Balancing 机制,在 DRAM 的 NUMA node 的剩余 memory 低于内存回收的 high 水位的时候,阻止其他 node 上的内存向其迁移。这让很多 PMEM 上的热页向 DRAM 的迁移变地不可能。
Ying Huang 童鞋在内核原有的内存回收 high 水位上,增加了一个 wmark_promo 的水位,比 high 水位高。在 DRAM 中,kswapd 回收到更高的 wmark_promo 的水位,把 cold pages 更多地挤压到 PMEM,从而为 PMEM 中的 cold pages 腾挪到 DRAM 提早腾出空间也避免 DRAM 内存被回收机制疯狂碾压。为什么选择这个方案,在多个方案中如何选择比对,大神在他的 commit 中描述地非常清晰:https://git.kernel.org/pub/scm/l ... t/?id=c574bbe917036
6.1 内核合入的来自 IBM Aneesh Kumar K.V 童鞋的“mm/demotion: Memory tiers and demotion” patchset,则允许把 memory tier 暴露给用户态,经由用户态进行配置。这弥补了内核态默认配置的很多不足,比如内核默认认为 cpu-less 的 memory 总是 lower tier,但是实际上它可能是 DRAM-backed 的高速内存;找比如默认的 demotion 路径比较死板,总是 demote 到下一级 tier 路径最短的 node,但是实际需求可能想要跨 socket demote 到其他更远的 node 上面去。
Aneesh Kumar K.V 童鞋提供的 patchset,允许用户透过设备驱动的接口, explicitly 而非 implicitly 配置相关的拓扑和 demotion 路径。

Rust 和 C 11
Linux 5.18 内核,决定迁移到 C 11 标准,以代替采用了 N 年的 C 89。C 89 的标准在内核统治了那么多年没有动摇,唯一只缺一根导火索了,而 Jakob Koschel 童鞋的“Proposal for speculative safe list iterator” patchset 就是这根导火索。
原本 Jakob 只是想修复潜在的不当使用 list_for_each_entry() 而引起的 bug。在内核最常见的 API list_for_each_entry() 的使用场景:
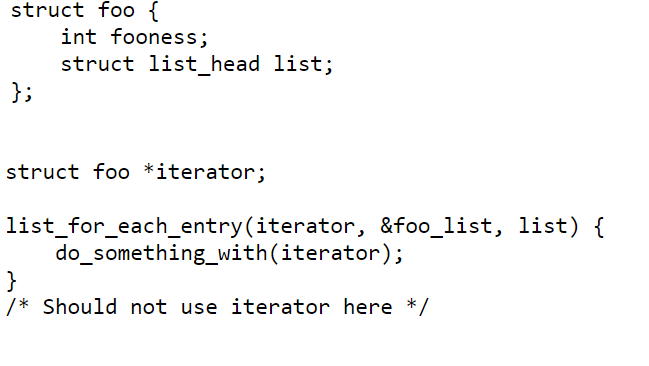
迭代器总是定义在 list_for_each_entry() 之外的,这导致循环迭代完成后,代码仍然可能访问 iterator,从而导致 bug,比如 Jakob 企图修复的其中一个“bug”就是:
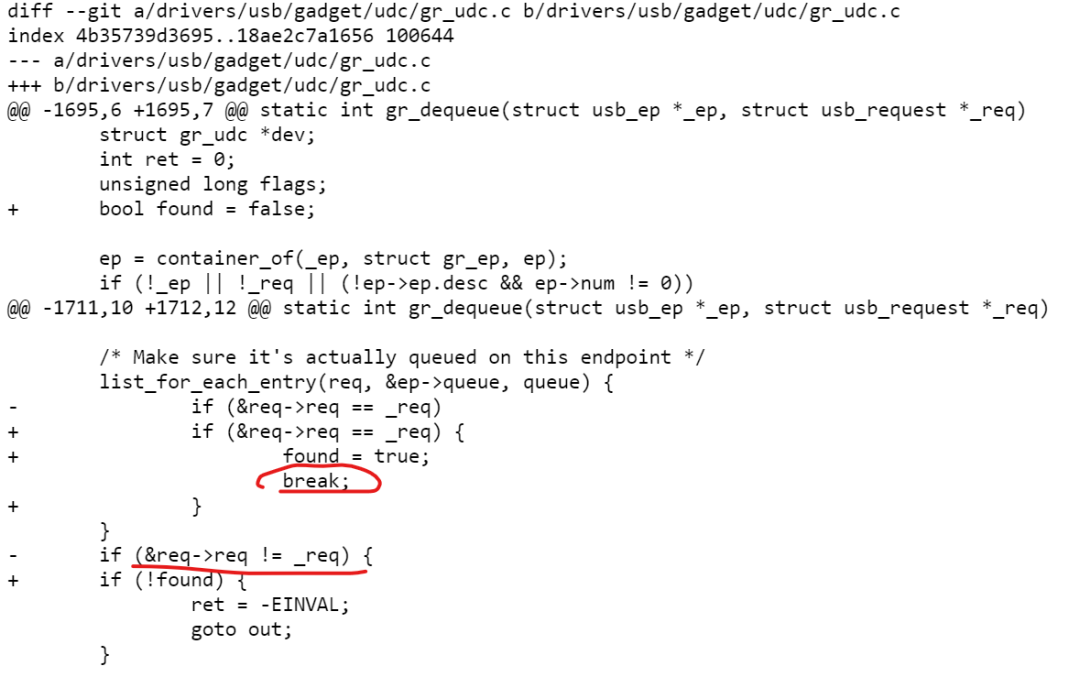
这个可能的“bug”的确有些狗血,哪怕 list_for_each_entry() 的循环没有查到,也即没有 break,最终指向 head 的 req 的 req->req 作为一片野内存,在各种内存排布的机缘巧合下仍然可能会等于 _req?
Jakob 猜中了这个故事的开头,却没有猜中这个故事的结局,他期待他的意中人驾着五色云彩来拯救他。而 Linus 最终选择的决定是:我们要潜在地支持让 iterator 可以在循环内部定义,定义在 loop 内部,外面想访问也访问不了,而C 89做不到:
The whole reason this kind of non-speculative bug can happen is that we historically didn't have C99-style "declare variables in loops". So list_for_each_entry() - and all the other ones - fundamentally always leaks the last HEAD entry out of the loop, simply because we couldn't declare the iterator variable in the loop itself.
——Linus Torvalds
在社区另一著名大神 Arnd Bergmann 的提议下,我们看到了最终现在看到的面向 C 11 的迁移。
关于内核支持 Rust,已经有无数的讨论,这里我们不再进行赘述。一些人坚信,Linux 内核支持 Rust 绝不是出于 Linus 的浪漫主义情怀,而更多是现实需要。因为 Rust 提供的生产环境以及编程效率远胜于 C,更加安全且 Rust 和 C 的性能可以做到不相上下。笔者大体认同这个观点,但 Rust 的浪漫仍然无法解救小码农现实的困顿。像笔者这样的类似《中国奇谭》小猪妖的底层打工仔而且是大龄的而言,只有一句话,那就是“命苦啊”。
前些年你们忽悠说,“人生苦短,请用 Python”,我气踹嘘嘘地去学 Python;Python 还没有学会,现在又被迫要学 Rust 了。由于 Linux 还有大量类似笔者这样的不思进取的码农阻碍科技的进步,相信 Rust 在最终的产品化和大行其道上,还有不少路要走。

热闹非凡的 BPF
2022 年的 Linux 社区,无疑充满了 BPF 的声音。这年头,内核码农嘴上不时时提几次 BPF,都不好意思出来跟人打招呼了。我们看到,不仅 BPF 本身的底层在完善,各个领域挂 BPF hook 的 patchset 层出不穷。这里我们举 2 个栗子。
大神 Tejun Heo 在调度器里面来深度参与 BPF,通过 BPF 扩展调度类。Tejun Heo 在 2022 年 11 月底,向内核社区发出一组 RFC,定义了一种新的调度类:ext_sched_class,允许调度策略经由 BPF 来实现。他认为,引入这个调度类,将有三方面重大好处:
- 快速地探索和部署调度策略的实验;
- 允许用户构造应用场景特定的调度策略;
- 在产线上无中断地部署新的调度策略。
这些说法,具有相当的合理性,内核调度器,强调设计的通用性,因此很难适配特定的用户场景。不停地发 patch 对 CFS 等调度策略进行微调,说实话,真地很蛋疼,倒不如把灵活性交给用户自己来决定,搞赢了算他的本事,搞输了他也得愿赌服输。RFC 上 cover letter 写地有理有据,实为我辈学习之楷模:https://lore.kernel.org/lkml/202 ... 17-1-tj@kernel.org/
这篇 cover letter 提到一个有意思的点,在 Meta,人们已经实验性采用机器学习来决定任务的调度策略。比如,机器学习可以帮忙预测一个 task 是不是很快要 yield CPU 了,如果是,那可以拦截 task 的 migration,因为迁过去只是浪费时间没必要,不如让它继续在本 CPU 上跑到 yield。比如有个人明天就要退休了,你今天还给他换个工作岗位,这就有点智障了,因为换岗位上下文切换熟悉新环境一天都不够吧?由此可见,由 BPF 实现调度策略,也便利了 AI 的部署,创造了更大的想象空间。
社区还在火热开发中的 BPF hooks 还有 HID-BPF,HID 是人机接口设备(Human Interface Devices),用于应付 USB 热插拔的 mice、keyboard 以及 Bluetooth, BLE, I2C, Intel/AMD Sensors 等。
在爱尔兰都柏林举行的 LPC 2022 上,来自红帽的 Benjamin Tissoires 童鞋解释,透过 BPF,我们可以节省大量的开发时间,比如一个简单的 HID “report descriptor”的 quirk,在内核里面开发需要经过 N 个步骤:识别问题、准备 patch 和测试、重新编译内存、提交补丁到 LKML、patch 的 LMKL 的 review、合入子树、合入 Linus 的树、成为 stable 的 branch 或者 backport 到 stable 的 branch、Linux 发行版采用新内核等漫长的过程。但是提供 BPF hook 的能力,就分分钟就可以搞定和部署了:
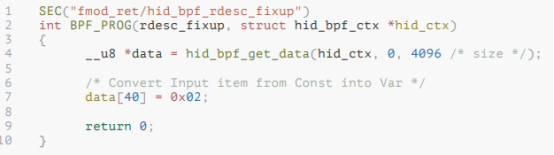
HID 中引入 BPF 的其他好处当然还有很多,比如在 hidraw 之外增强 tracing,提供 HID firewall 等。
BPF 为内核的向外衍生提供了无穷的可能性,梦想有多远,你就可以走多远,这种可能性甚至超越了子系统的界限。

龙芯新架构 LoongArch 引入 5.19 内核主线
最后压轴的榜单,荣耀归于龙芯。陈华才老师等以艰苦卓绝的工作,征服了 Linux 社区,将龙芯新架构 LoongArch 注入了 Linux 内核。这一点,在我国技术时时被人“卡脖子”的今天,尤其显得弥足珍贵。
LoongArch 是一种完全不同于 Loongson 的体系架构,不同于老的 Loongson采用 MIPS 指令集,LoongArch 则是一种全新的指令集。Loongson- 3A5000 后续较新的 Loongson 芯片,就采用了这种全新的 LoongArch 指令集。
正在上传…重新上传取消
与常见的 RISC-V、ARM 等体系架构类似,LoongArch 包括 general purpose registers (GPRs), floating point registers (FPRs), vector registers (VRs) 以及 control status registers (CSRs)。LoongArch 有 4 个不同的privilege levels (PLVs) :PLV0~PLV3,内核运行于 PLV0,而用户态运行于 PLV3。
不同于在一个现有的体系架构下增加一个新的 SoC 支持,在 Linux 内核增加一个全新体系架构支持的工作要艰巨很多,它至少包含但不限于如下工作:
1.开机初始化和启动
2.进程上下文保存恢复
3.exception 进入退出
4.各种 exception 的处理
5.中断进入退出
6.中断屏蔽和恢复 API
7.中断控制器管理
8.cache、TLB、内存管理
9.spinlock、atomic 等的支持
10.系统调用支持
11.串口 console
12.电源管理支持
13.调试工具比如 ftrace 等的支持
14.BPF 支持
这是实打实的软硬结合的编程硬功夫,来不得半点偷懒,缺陷代码也没有半点幸存的空间。
到这里,我们基础陈述完了 2022 年内核社区这些重要的技术革新。

总结
2022 年的地球局势诡谲莫测,而我国 Linux 社区仍像一柄利刃一样,穿透阴霾,展现出无限的生机和活力。
华为的 Linux 内核开发者们,以无与伦比的勤奋和技术实力,多次成为内核开发贡献榜的大满贯赢家;郭寒军、吴峰光等技术领袖为代表的 OpenEuler 内核社区,海纳百川。
字节以段雄春、宋牧春等为代表的火山云引擎内核开发组,不断给内核增加新的优化;在朋友圈膜拜合影上贵组诸位大神的强大气场,令人钦佩不已。
阿里巴巴的工程师们,在内核 crypto、DAMON、virtio、erofs、RDMA、riscv、调度器、内存管理等模块,不断做出新的突破。
腾讯的内核开发者们,在 KVM、io_uring、网络、perf 等模块披荆斩棘。
陈华才老师的团队,将龙芯新架构 LoongArch 引入 5.19 内核主线。
清华的陈渝老师,仍然在低调地向青年们传授着 OS 内核技术;而陈莉君老师和张国强老师,甚至领导和组织了第一届全国 BPF 技术大会,众多厂商和高校带着他们的项目和研究参会。
秋季由清华大学、Intel、华为、阿里云、富士通南大、迪捷软件、腾讯云、OPPO、字节跳动等企业发起的 2022“中国Linux内核开发者大会”在线上举行,依旧收获了粉丝们高涨的热情、吸引了最广泛的受众。
新的一年里,更期待我敬仰的老一辈内核大神们,李勇、吴峰光、黄瀛、时奎亮、李泽帆等大神童鞋,凭借自身丰富的国际社区参与和一线工作的经验,发挥领袖作用,进一步把我们的年青一代内核码农们引入国际社区,带到 LPC 上去,带到其他开源论坛上去,让更多好的 idea 成为 Linux 内核的代码。更期待以陈莉君老师、陈渝老师为领袖的授业力量,以及 Linux 内核之旅、内核工匠、蜗窝科技、Linux 阅码场、Linux 中国、泰晓科技、奔跑吧等技术社区关注高质量内容,将 Linux 内核的知识传播与普及,形成百舸争流、百花齐放的开放学术格局。
亲爱的童鞋们,2023 兔年新春的钟声即将敲响,满饮了此杯,忘却往日的悲伤徘徊,吹起嘹亮的号角,去战斗吧。我们战斗在调度器的田野,我们战斗在性能优化的山岗,我们战斗在内存管理的星辰,我们战斗在文件系统的大海。用我们的内核代码,延伸生命的物理长度,成就传奇。人生虽充满无穷尽变数,我们虽控制不了苦难,但是我们仍大抵可以掌控自己的代码。
作者简介:
宋宝华,长期的一线 Linux 内核开发者,工作于内核调度器、内存管理、ARM/ARM64 arch、设备驱动等领域,向内核提交了数百个补丁。
参考文献
【1】 Using Linux Kernel Memory Tiering
https://stevescargall.com/2022/0 ... nel-memory-tiering/
【2】kernel changelog
https://kernelnewbies.org/Linux_5.16
https://kernelnewbies.org/Linux_5.17
https://kernelnewbies.org/Linux_5.18
https://kernelnewbies.org/Linux_5.19
https://kernelnewbies.org/Linux_6.1
【3】LPC 2022 eBPF & Networking
https://lpc.events/event/16/sessions/131/#all
【4】The Maple Tree
https://lpc.events/event/4/contr ... _LPC_Maple_Tree.pdf
【5】Overview of Memory Reclaim in the Current Upstream Kernel
https://lpc.events/event/11/cont ... /1493/slides-r2.pdf
|
|




 发表于 2023-1-23 22:46:10
发表于 2023-1-23 22:46:10